Seven Hours, Zero Internet, and Local AI Coding at 40,000 Feet
Published on
Seven hours on a plane, zero internet, and a curiosity about local AI coding. That’s how I found myself downloading 13GB of AI models in an airport lounge, preparing for what would become an accidental experiment in offline development.
This wasn’t a research project or a formal comparison of existing solutions. I was heading back from vacation with a long flight ahead and wanted to avoid getting bored. The idle question nagging at me: what would it be like to have a coding assistant totally local, or at least that I can run on my own infrastructure, without paying for tokens or subscriptions? Plus, it sounded fun.
So I decided to find out where we are on this path.

What I Threw Together Before Takeoff
I started from a basic Next.js project with the dependencies I like: TailwindCSS, Zod, ts-pattern, etc. My goal was to use a stack I already know very well, so I wouldn’t be fighting unfamiliar tools while experimenting with local AI.
Then, with the quest for a local LLM, came the real trial and error. I tried Devstral from Mistral, Qwen3, with Crush, OpenCode and Ollama-code. After several failed attempts, gpt-oss was actually the only one I was able to make work, and only with OpenCode1. It’s not that I did extensive research to compare solutions – this was purely what I could get functioning in the time I had.
So I set up Ollama with gpt-oss downloaded – all 13GB of it. My machine is a MacBook Pro M4 Pro with 24GB of RAM, which I should mention upfront because the hardware requirements turn out to matter quite a bit.
For the project itself, I chose something deliberately simple: an app to track subscriptions to recurring services like Netflix or your gym. Basic CRUD operations, nothing fancy. I decided to make the app rely on the browser’s local storage to persist data, instructing the assistant to create an abstraction on top of it so I could migrate to a proper API or Supabase later.
Seven Hours at 40,000 Feet
For my experiment, I used the approach I described in Turning Claude Code Into My Best Design Partner: first I ask the assistant to plan the feature, following up with changes if necessary. When the plan looks good, I ask to put it in a Markdown file in a plans folder. Then I ask it to start implementation using the plan and update the plan document with progress, making it a living document.
I was pleasantly surprised that the planning was more than okay, at least for my basic use case. Maybe it would be more complicated for a more complex feature, but here I accepted the suggested plans almost at first try!
The speed reality hit quickly: the local setup was about 4-5x slower than Claude Code2, so you have to be patient. Good thing planes have movies to watch between the prompts.
The energy consumption was the real surprise. Not only were my thighs quite burning from the laptop heat, but the power offered by the plane – with its shitty plug – wasn’t able to compensate for the energy that the local model needed. I had to take breaks at some points to let my laptop’s battery charge. Forget about battery-powered coding sessions.
Finally, the code quality was usually 95% correct, but fixing the remaining 5% was tedious. Various issues kept cropping up: ESLint problems, using
anyinstead of proper types, or some UI elements that got removed from one iteration to another, like buttons that would just disappear. In a professional project, I would have fixed these issues myself for speed reasons. Here, I wanted to go all in with the AI-assisted approach, but the AI was perfectly capable of fixing the problems – it just took a lot of time and iterations.
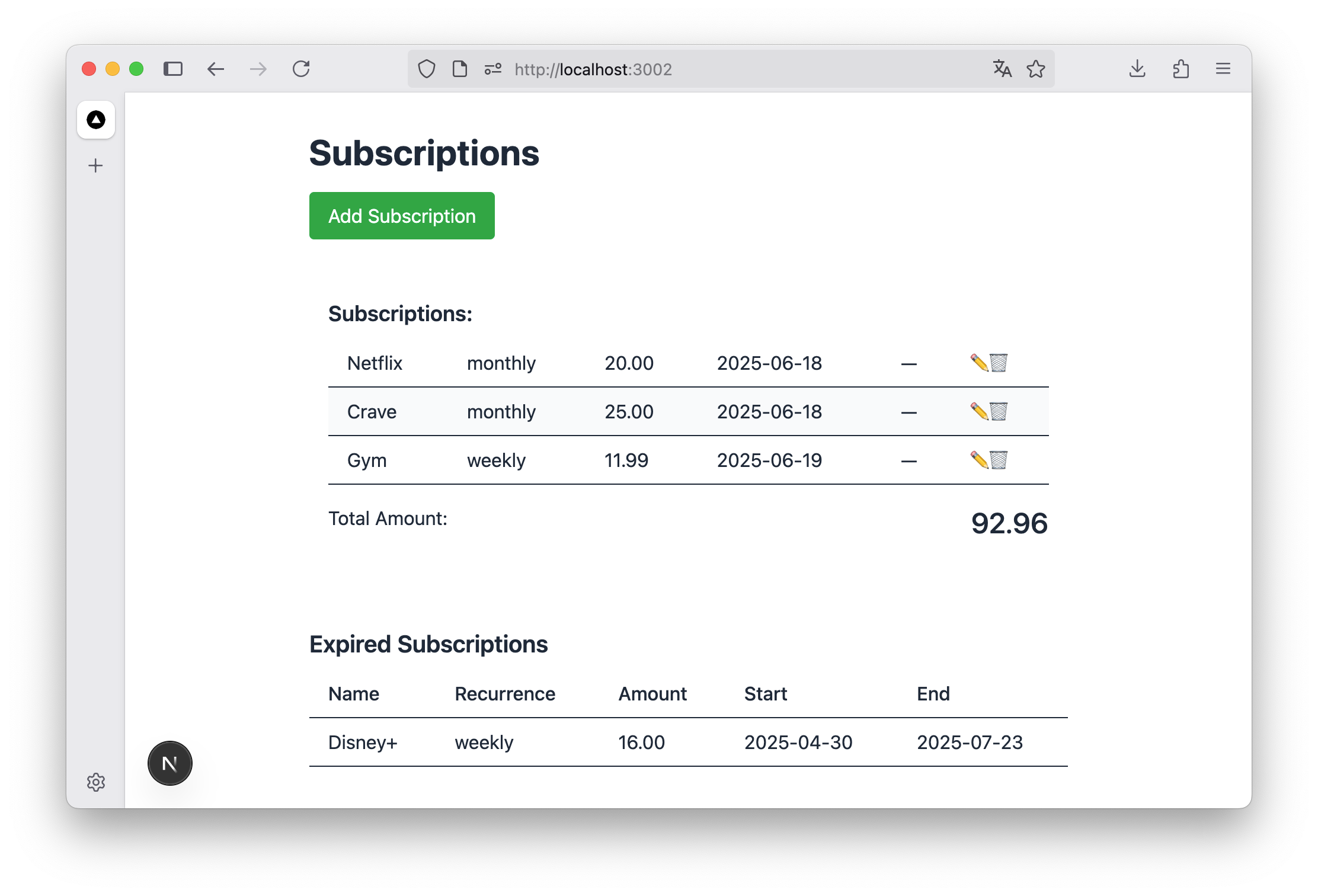
The subscriptions list in the resulting app. Not an app I would use everyday, but it works :)
During my 7-hour flight, I worked on the app for about 3-4 hours (the rest being meals, naps and movies). I was able to build a basic app with a form to add a subscription, a subscription list showing the total for the current month plus expired and future subscriptions, an edit button, and a way to delete subscriptions. The UI was very basic and not very UX-friendly, but it worked.
The Broader Reality Check
When I started using OpenCode with gpt-oss, I was pleasantly surprised to see that it just worked. Not perfect, but pretty good. And all on my machine only! No need to check my Claude quotas or API keys usage. There was something liberating about that complete independence.
The latency that a local model implies, plus the energy consumption, make it hard to imagine going fully local for now. The hardware requirements are real – this isn’t running smoothly on your average developer laptop. But let’s hope performance and efficiency will improve over time.
Finally, I would have expected to have more documented options at my disposal for local AI coding. I was able to find some blog posts, some outdated, but official documentation was lacking with OpenCode3, Crush4, and similar tools.
The next thing I’d like to try is using OpenAI’s GPT-OSS with OpenCode, but not locally: either from OpenAI’s API, or from a server with more power than my laptop.
What This Actually Means
Looking at this experiment, the most important takeaway for practitioners is a mix between “local AI coding is surprisingly viable today” and “it’s still too early but getting close.”
It’s really about having the option to go local, plus the hope that someday the models will be more efficient and the hardware more AI-optimized, so that everything can run locally and smoothly without consuming too much energy or destroying batteries.
The current state is encouraging for simple projects but still feels early for serious professional work. The trade-offs are real: you need serious hardware, you’ll burn through battery life, and you’ll move slower than with cloud-based tools. But the foundation is there, and it’s more solid than I expected.
Back to Reality
Landing, turning WiFi back on, returning to Claude Code – the speed difference was immediately apparent. But something had shifted during those seven hours offline. Local AI coding moved from “maybe someday” to “definitely possible, with caveats.”
This vacation experiment accidentally revealed where we are on the path to truly local development assistance. We’re not there yet, but we can see it from here. And sometimes, that’s the most interesting place to be.
I used this guide to set up OpenCode with gpt-oss using Ollama. ↩︎
Only my personal feeling, it’s hard to get a precise benchmark. ↩︎
See this short section about setting up OpenCode with Ollama. ↩︎
This section in Crush’s documentation explains how to use it with Ollama, but all models I’ve tried using generated errors related to tool-calling… ↩︎