Sept heures, zéro internet, et du coding IA local à 13 000 mètres
Publié le
Sept heures d’avion, zéro internet, et une curiosité pour le coding IA local. Voilà comment je me suis retrouvé à télécharger 13 Go de modèles IA dans un salon d’aéroport, me préparant pour ce qui allait devenir une expérience accidentelle de développement hors ligne.
Ce n’était pas un projet de recherche ou une comparaison formelle des solutions existantes. Je rentrais de vacances avec un long vol devant moi et je voulais éviter de m’ennuyer. La question qui me taraudait : à quoi ça ressemblerait d’avoir un assistant de coding totalement local, ou du moins que je puisse faire tourner sur ma propre infrastructure, sans payer de tokens ou d’abonnements ? En plus, ça avait l’air fun.
J’ai donc décidé de voir où on en est sur ce chemin.

Ce que j’ai bricolé avant le décollage
J’ai commencé avec un projet Next.js basique avec les dépendances que j’aime : TailwindCSS, Zod, ts-pattern, etc. Mon objectif était d’utiliser une stack que je connais très bien, pour ne pas me battre avec des outils inconnus tout en expérimentant avec l’IA locale.
Puis, avec la quête d’un LLM local, est arrivé les vrais essais-erreurs. J’ai essayé Devstral de Mistral, Qwen3, avec Crush, OpenCode et Ollama-code. Après plusieurs échecs, gpt-oss est devenu le seul que j’ai réussi à faire fonctionner, et seulement avec OpenCode1. Ce n’est pas que j’ai fait des recherches approfondies pour comparer les solutions – c’était simplement ce que j’arrivais à faire marcher dans le temps que j’avais.
J’ai donc configuré Ollama avec gpt-oss téléchargé – 13 Go au total. Ma machine est un MacBook Pro M4 Pro avec 24 Go de RAM, ce que je devrais mentionner d’emblée car les exigences hardware s’avèrent assez importantes.
Pour le projet en lui-même, j’ai choisi quelque chose de délibérément simple : une app pour tracker les abonnements aux services récurrents comme Netflix ou ta salle de sport. Des opérations CRUD basiques, rien de fancy. J’ai décidé de faire reposer l’app sur le local storage du navigateur pour persister les données, en demandant à l’assistant de créer une abstraction par-dessus pour pouvoir migrer vers une vraie API ou Supabase plus tard.
Sept heures à 13 000 mètres
Pour mon expérience, j’ai utilisé l’approche que j’ai décrite dans Faire de Claude Code mon meilleur partenaire de design : d’abord je demande à l’assistant de planifier la feature, en donnant des retours si nécessaire. Quand le plan a l’air bon, je lui demande de le mettre dans un fichier Markdown dans un dossier plans. Puis je lui demande de commencer l’implémentation en utilisant le plan et de mettre à jour le document de plan avec les progrès, en faisant un document vivant.
J’ai été agréablement surpris que la planification soit plus que correcte, du moins pour mon cas d’usage basique. Peut-être que ce serait plus compliqué pour une feature plus complexe, mais là j’ai accepté les plans suggérés presque du premier coup !
La réalité de la vitesse a frappé rapidement : la config locale était environ 4-5x plus lente que Claude Code2, donc il faut être patient. Heureusement que les avions ont des films à regarder entre les prompts.
La consommation d’énergie était la vraie surprise. Non seulement mes cuisses brûlaient à cause de la chaleur du laptop, mais l’alimentation fournie par l’avion – avec sa prise de merde – n’arrivait pas à compenser l’énergie que le modèle local nécessitait. J’ai dû faire des pauses à certains moments pour laisser la batterie de mon laptop se charger. Oublie les sessions de coding sur batterie.
Enfin, la qualité du code était généralement correcte à 95%, mais corriger les 5% restants était fastidieux. Divers problèmes continuaient à surgir : problèmes ESLint, utilisation d’
anyau lieu de types appropriés, ou des éléments d’UI qui disparaissaient d’une itération à l’autre, comme des boutons qui s’évaporaient. Dans un projet pro, j’aurais corrigé ces problèmes moi-même pour des raisons de rapidité. Là, je voulais aller all-in avec l’approche assistée par IA, mais l’IA était parfaitement capable de corriger les problèmes – ça prenait juste beaucoup de temps et d’itérations.
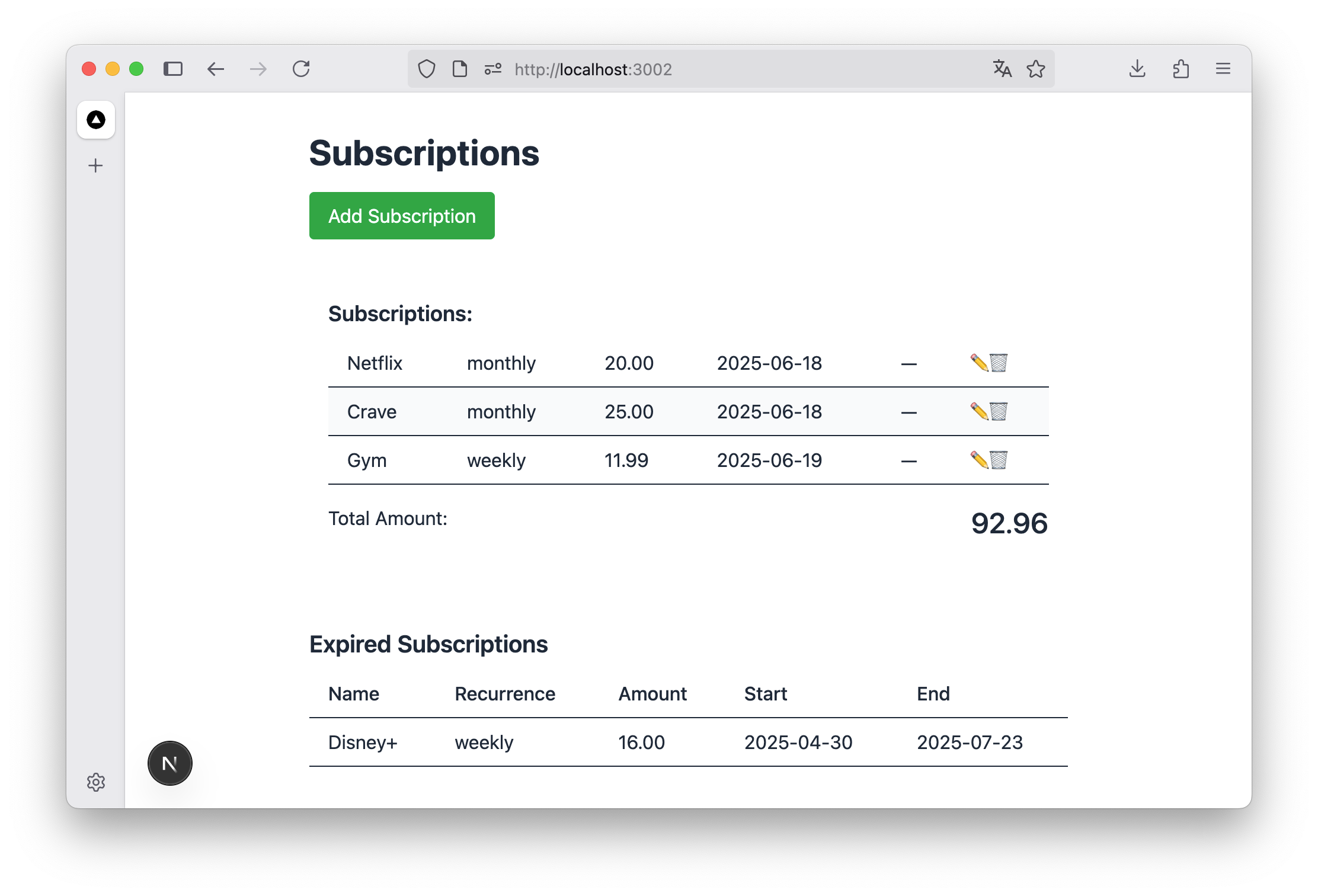
La liste des abonnements dans l’app résultante. Pas une app que j’utiliserais tous les jours, mais ça marche :)
Pendant mon vol de 7 heures, j’ai travaillé sur l’app pendant environ 3-4 heures (le reste étant des repas, siestes et films). J’ai réussi à construire une app basique avec un formulaire pour ajouter un abonnement, une liste d’abonnements montrant le total pour le mois en cours plus les abonnements expirés et futurs, un bouton d’édition, et un moyen de supprimer les abonnements. L’UI était très basique et pas très UX-friendly, mais ça marchait.
Le reality check plus large
Quand j’ai commencé à utiliser OpenCode avec gpt-oss, j’ai été agréablement surpris de voir que ça marchait tout simplement. Pas parfait, mais plutôt bien. Et tout ça sur ma machine seulement ! Pas besoin de vérifier mes quotas Claude ou l’usage de mes clés API. Il y avait quelque chose de libérateur dans cette indépendance complète.
La latence qu’implique un modèle local, plus la consommation d’énergie, rendent difficile d’imaginer passer entièrement en local pour l’instant. Les exigences hardware sont réelles – ça ne tourne pas facilement sur le laptop moyen d’un développeur. Mais espérons que les performances et l’efficacité s’amélioreront avec le temps.
Enfin, je me serais attendu à avoir plus d’options documentées à ma disposition pour le coding IA local. J’ai pu trouver quelques articles de blog, certains obsolètes, mais la documentation officielle manquait avec OpenCode3, Crush4, et des outils similaires.
La prochaine chose que j’aimerais essayer c’est d’utiliser GPT-OSS d’OpenAI avec OpenCode, mais pas localement : soit depuis l’API d’OpenAI, soit depuis un serveur avec plus de puissance que mon laptop.
Ce que ça signifie vraiment
En regardant cette expérience, le takeaway le plus important pour les praticiens est un mélange entre “le coding IA local est étonnamment viable aujourd’hui” et “c’est encore trop tôt mais on s’en rapproche.”
C’est vraiment histoire d’avoir l’option d’aller en local, plus l’espoir qu’un jour les modèles seront plus efficaces et le hardware plus optimisé pour l’IA, pour que tout puisse tourner localement et en douceur sans consommer trop d’énergie ou détruire les batteries.
L’état actuel est encourageant pour des projets simples mais semble encore précoce pour du travail professionnel sérieux. Les trade-offs sont réels : tu as besoin d’un hardware puissant, tu vas brûler ta batterie, et tu iras plus lentement qu’avec des outils cloud. Mais la fondation est là, et elle est plus solide que je ne m’y attendais.
Retour à la réalité
Atterrissage, rallumer le WiFi, retour à Claude Code – la différence de vitesse était immédiatement apparente. Mais quelque chose avait changé pendant ces sept heures hors ligne. Le coding IA local est passé de “peut-être un jour” à “définitivement possible, avec des bémols.”
Cette expérience de vacances a accidentellement révélé où on en est sur le chemin vers une assistance au développement vraiment locale. On n’y est pas encore, mais on peut le voir d’ici. Et parfois, c’est l’endroit le plus intéressant où se trouver.
J’ai utilisé ce guide pour configurer OpenCode avec gpt-oss en utilisant Ollama. ↩︎
Seulement mon ressenti personnel, c’est difficile d’avoir un benchmark précis. ↩︎
Voir cette courte section sur la configuration d’OpenCode avec Ollama. ↩︎
Cette section dans la documentation de Crush explique comment l’utiliser avec Ollama, mais tous les modèles que j’ai essayés ont généré des erreurs liées au tool-calling… ↩︎